
When talking about data sets, “Big Data” refers to those that are too large or complicated to be processed by conventional data-processing software. The statistical power of data with more fields (rows) is greater, whereas data with greater complexity (more attributes or columns) may result in a higher false discovery rate. Capturing data, storing data, analyzing data, searching, sharing, transferring, visualizing, querying, updating, maintaining information privacy, and identifying the data source are all obstacles to big data analysis. Initially, big data was associated with three fundamental concepts: volume, variety, and velocity. In the past, only observations and sampling were permitted due to the difficulties posed by the analysis of large data sets. Thus, a fourth concept, veracity, refers to the data’s quality or insight. Without sufficient investment in expertise for big data veracity, the volume and variety of data can result in costs and risks that exceed a company’s ability to create and extract value from big data.
The characteristics of Big Data
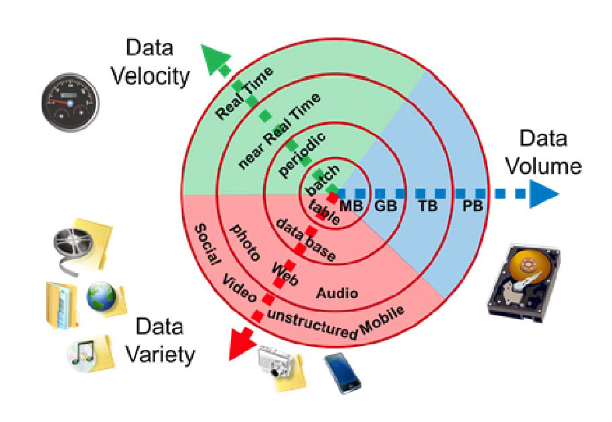
- Volume – The amount of data is important. With big data, you will be required to process large quantities of low-density, unstructured data. This can include Twitter data feeds, clickstreams on a website or mobile application, and sensor-enabled equipment. This could be tens of terabytes of data for some organizations. It may be hundreds of petabytes for others.
- Velocity – This is the rate at which data is received and (potentially) acted upon. Typically, the highest rate of data transfer occurs directly into memory as opposed to being written to disk. Some internet-enabled intelligent products operate in real time or close to real time, necessitating real-time evaluation and action.
- Variety – Variety refers to the numerous types of available data. In a relational database, traditional data types were structured and easily accommodated. With the rise of big data, new unstructured data types have emerged. Text, audio, and video are examples of unstructured and semi-structured data types that require additional preprocessing to extract meaning and support metadata.
- Variability – This refers to the data’s occasional inconsistency, which hinders the ability to effectively manage and handle the data.
Importance
A company can increase its revenue and profits by using big data in its systems to enhance its operations, deliver superior customer service, develop targeted marketing campaigns, and do other things. Businesses that use it effectively have a potential competitive advantage over those that don’t because they can make decisions more quickly and with more information.
Big data can help businesses improve their marketing, advertising, and promotions, for instance, by revealing previously unknown facets of their target audiences. Both historical and real-time data can be analyzed to assess the changing preferences of consumers or corporate buyers, allowing businesses to be more responsive to customer needs.
Medical researchers use big data to identify disease symptoms and risk factors, and physicians use it to aid in the diagnosis of diseases and medical conditions. In addition, a combination of data from electronic health records, social media sites, the Internet, and other sources provides healthcare organizations and government agencies with current information regarding infectious disease threats or outbreaks.
Challenges
First of all, despite the development of new data storage technologies, data volumes double approximately every two years. Organizations continue to struggle to effectively store and keep up with their data.
But it is not sufficient to simply store the data. To be valuable, data must be utilized, and this requires curation. Clean data, or data that is relevant to the client and organized in a way that permits meaningful analysis, requires a significant amount of effort. Before data can be used, data scientists spend between 50 and 80 percent of their time curating and preparing it.
Finally, big data technology is rapidly evolving. A few years ago, Apache Hadoop was the prevalent technology for handling large amounts of data. Then, in 2014, Apache Spark was introduced. Currently, a combination of the two frameworks appears to be the most effective strategy. Keeping up with the technology of big data is a constant challenge.
Some pros and cons
The increase in available data presents both opportunities and challenges. Having more information about customers (and potential customers) should enable businesses to better tailor their products and marketing efforts in order to maximize customer satisfaction and repeat business. Large-scale data collection affords businesses the opportunity to conduct more in-depth and comprehensive analyses for the benefit of all stakeholders.
With the amount of personal data available on individuals today, it is imperative that companies take steps to protect this data, a topic that has become a hot topic in the online world, especially in light of the numerous data breaches companies have experienced in recent years.
While improved analysis is a positive, big data can lead to information overload and noise, diminishing its utility. Companies must manage greater data volumes and determine which data represents signals as opposed to noise. Identifying what makes the data relevant becomes a crucial consideration.
In addition, the nature and format of the data may necessitate special treatment prior to action. Structured data consisting of numeric values are simple to store and sort. Before unstructured data, such as emails, videos, and text documents, can be useful, more sophisticated techniques may need to be applied.

Leave a comment